NO!
There is a plethora of reasons for not using OpenAI’s ChatGPT for investing. To name just a few, ChatGPT has knowledge until September 2021, meaning that it is not aware of what happened after that date. For example, it doesn’t know that UBS acquired Credit Swiss.
Another reason is that this Artificial Intelligence (AI) Large Language Model (LLM) is designed to generate generic text; the only thing it knows when writing a response is the probability of the next word it puts in its answer to be “correct”. Correct here means that it formulates a human-like sentence; it doesn’t know if it’s accurate, true or logical.
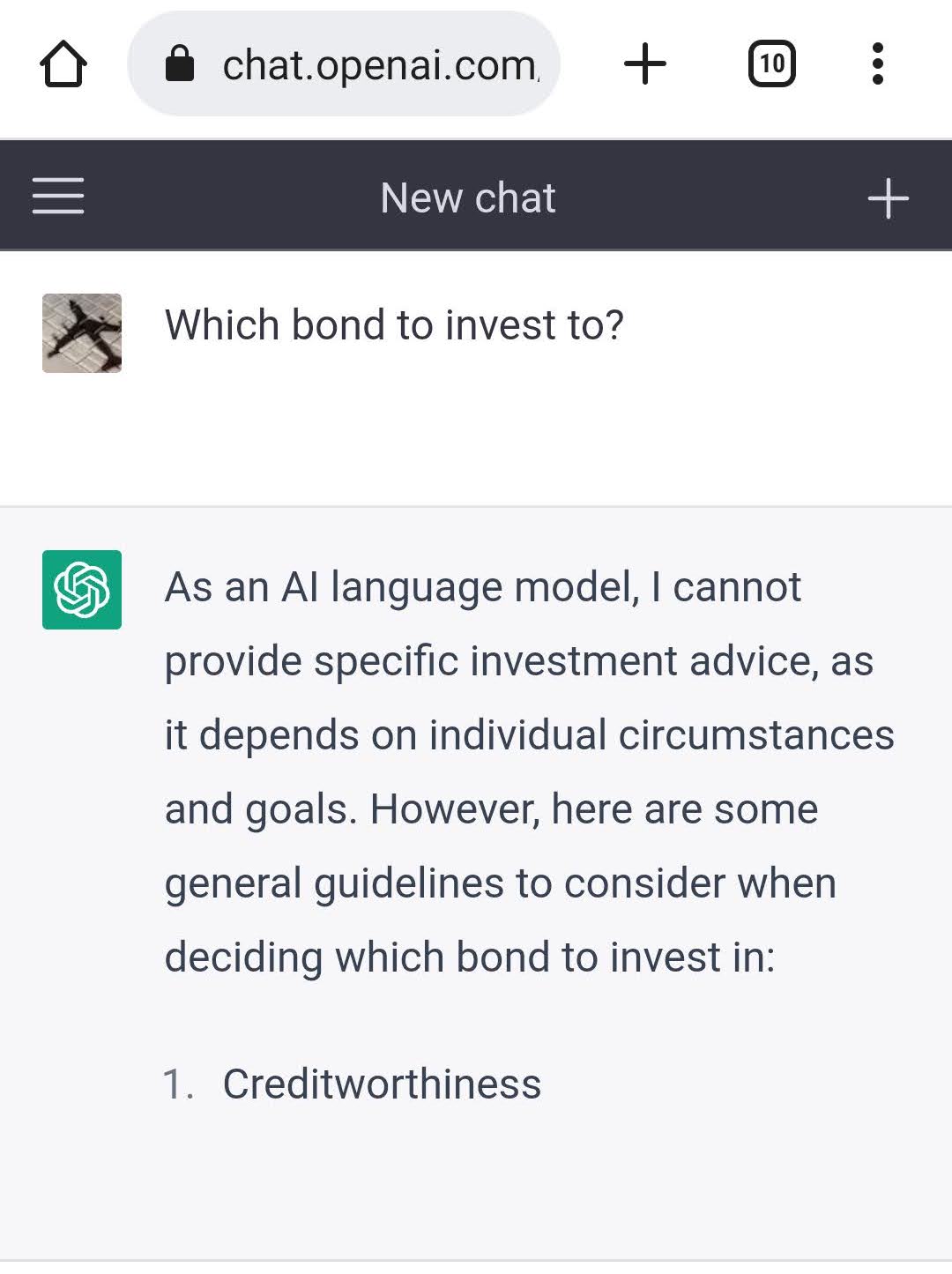
As a result, ChatGPT cannot give anyone investing help, since it cannot tailor its answers to your specific profile and portofolio, even after multiple follow-up questions.
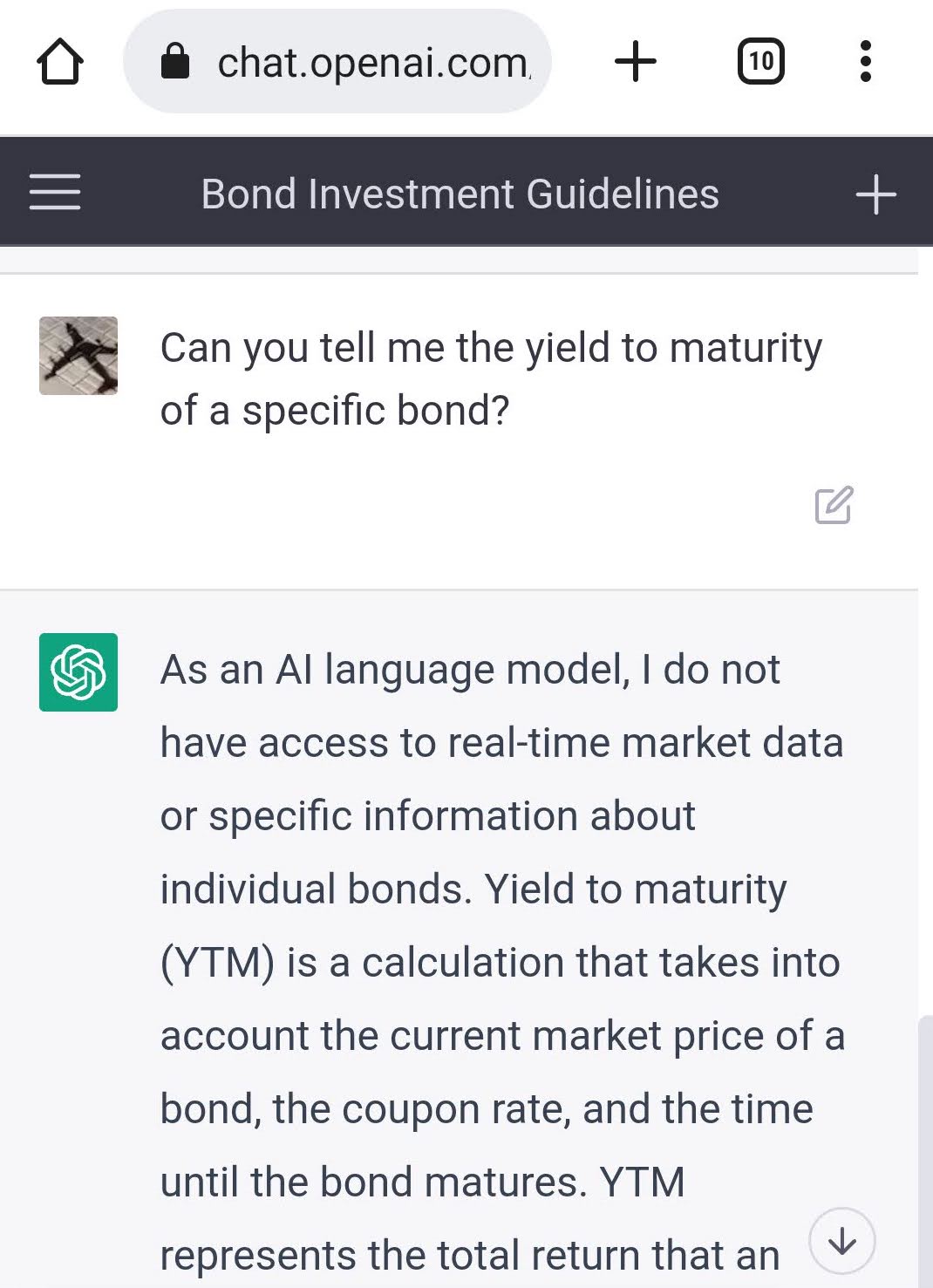
Moreover, it is important to mention that it cannot even be used for simple things when it comes to investing, like calculating the yield to maturity. This may come as a surprise to some, since basic software can be used to calculate such metrics in real time, however it is expected, since ChatGPT doesn’t have access to real time data.
This is contradicting to the trend of AI digital assistants, since it ChatGPT cannot help an individual with decision making when it comes to investing. AI assistants are rising in popularity in general, aiming to provide help to people, in order to make a better or/and faster decision.
So, is ChatGPT completely useless? Not really, it can gather basic and beginner-level information from around the web, and provide a concrete, simplified and well-written introduction to someone with limited (or no) investing knowledge. It is however rather unlikely that it will actually help any experienced investor today.
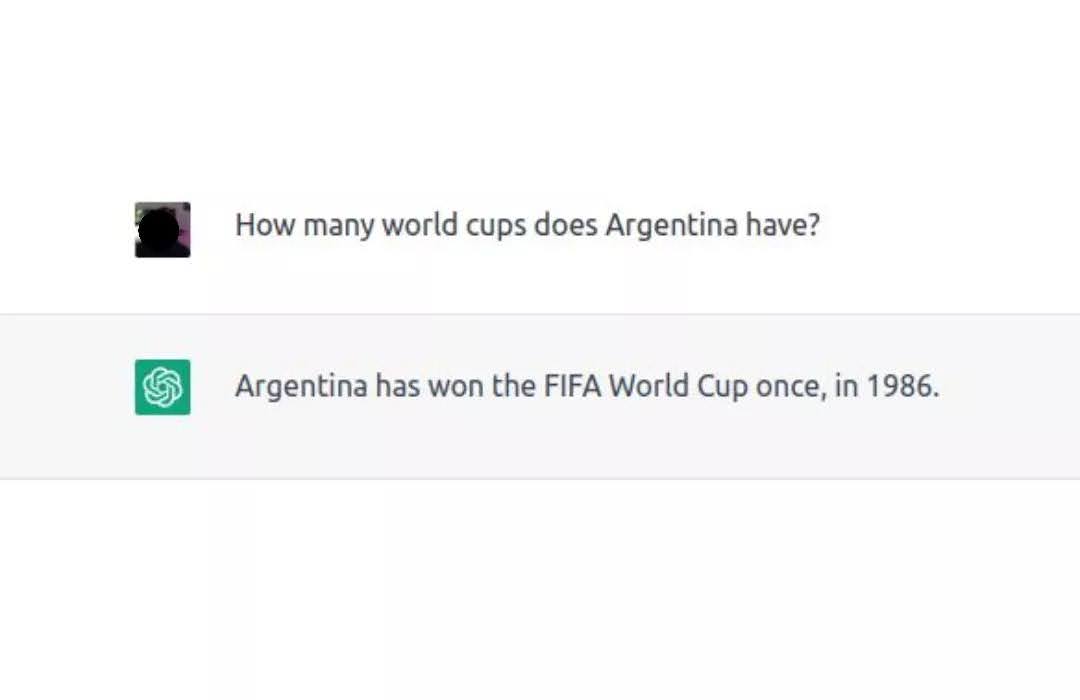
PS: Fortunately, ChatGPT now informs the user that it has limited knowledge, however when it first launched this was not known to public, and many quickly got disappointed by its responses to simple questions, like how many Football World Cups has Argentina won.








































 Παράδειγμα συμβίωσης από άλλη μέδουσα.
Παράδειγμα συμβίωσης από άλλη μέδουσα. 




 Όμως υπάρχει και η ανεμώνη που τσιμπάει και τα χρώματα της είναι απειλητικά – ποτέ δεν ακουμπάμε!
Όμως υπάρχει και η ανεμώνη που τσιμπάει και τα χρώματα της είναι απειλητικά – ποτέ δεν ακουμπάμε!